How message-driven orchestration is replacing request-response integration

Enterprise integration makes designing, exposing, and reusing exponentially easier with API-first architecture. Facilitating intuitive and immediate responses is a priority and an essential aspect of system-to-system communication, supported by REST APIs, SOAP services, and webhooks.
Yet there's a huge gap in its extensibility. It's amorphous enough to handle lightweight workflows spanning a few systems, but when the scenario scales up to juggling multiple workflows across many systems, it struggles to keep up. This limitation becomes especially clear when the variables involve human approvals, touch private network resources, and invariably can continue for minutes, hours, or days to resolve. A synchronous API call isn't designed to wait while an order clears validation, a manager approves access, a server task completes, or an audit record is created.
That's where message-driven orchestration becomes useful. Instead of forcing every system to respond immediately, events and messages can trigger workflow execution, route work across systems, and preserve state until the next step is ready.
The important question isn't whether APIs or messages are better, but when to use each pattern, where to deploy them, and how to orchestrate both seamlessly, without ever losing visibility, governance, and control.
The API purist approach has its limitations
API-first integration works well when the interaction is direct, predictable, and time-sensitive. A customer checking payment status, a user submitting a form, or a system retrieving a record can use synchronous request-response communication effectively.
A synchronous API call isn’t designed to wait while an order clears validation, a manager approves access, a server task completes, or an audit record is created.
API-first patterns are strong for:
- Simple point-to-point integrations
- Immediate validation or response requirements
- Lightweight data exchange
- Exposing controlled services to trusted consumers
- Standard REST or SOAP interactions
When API calls become the sole proprietor for an entire workflow lifecycle, contained in isolation, it becomes a problem. In that model, the caller waits while downstream systems complete their work. If several services are strung together, a single delay can cascade across the entire process.
Common API-first limits include:
- Timeout risk: HTTP clients, gateways, proxies, and platforms usually enforce request timeouts. The exact limit varies, so long-running work shouldn't be designed around a single synchronous call.
- Tight coupling: The caller depends on the receiver being available and responsive at that moment.
- Back-pressure: If the receiver is overloaded, the caller must retry, fail, or build its own queueing logic.
- Failure cascades: If one downstream system is unavailable, upstream systems may also fail, wait, or repetadly retry the same request, increasing the load across the chain.
- Hidden workflow state: APIs can confirm that a request has been accepted, but they don't automatically indicate where the process is now.
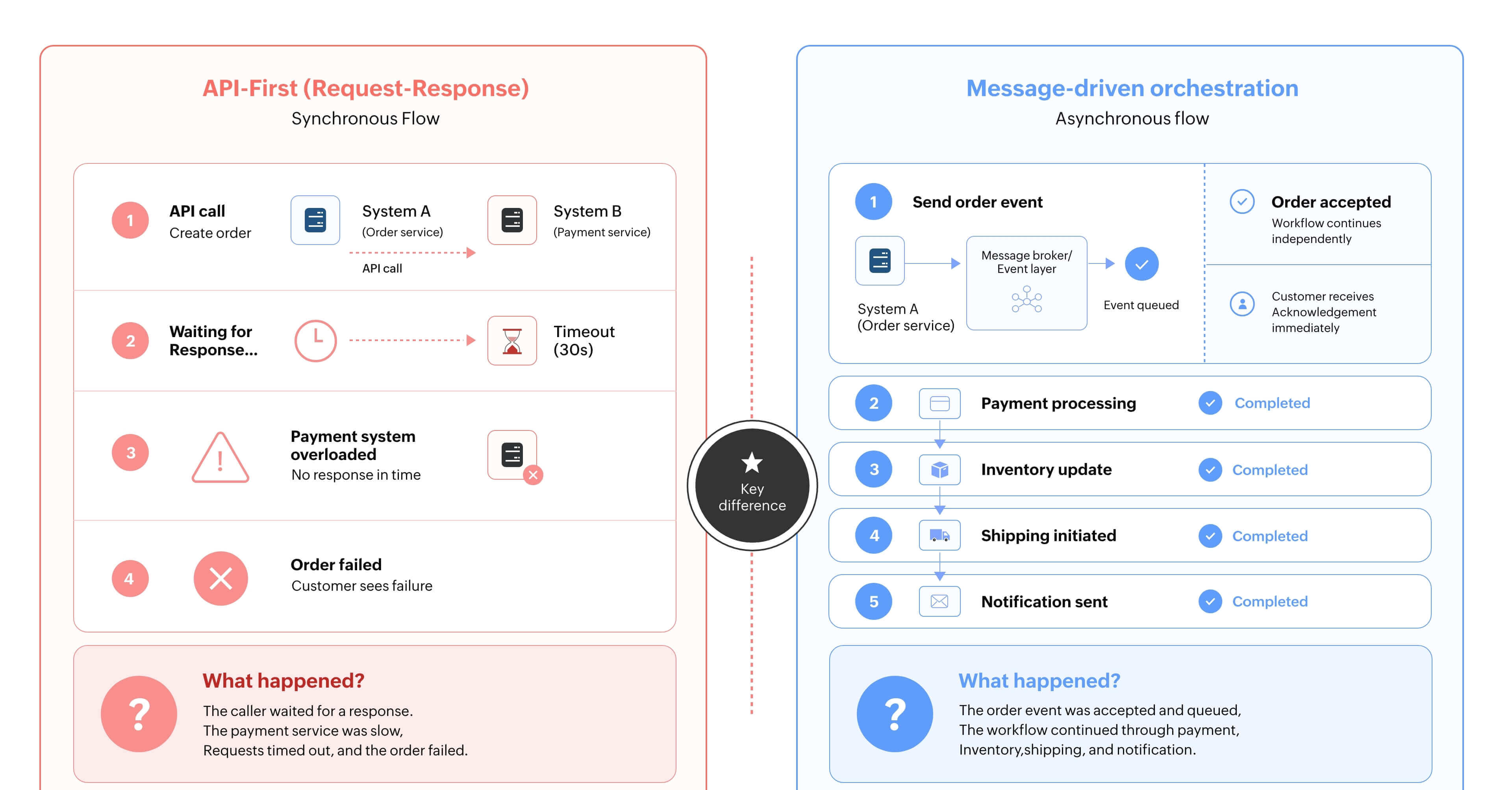
Take an order-to-payment workflow. A customer submits an order, the payment service is busy, and the API call times out. From the customer's view, the order failed, but the business requirement may not be immediate completion. It may be reliable processing, retrying, auditing, and eventual confirmation.
A message-driven pattern handles this differently. The order event is accepted, queued, or routed, correlated with a workflow instance, and processed when downstream systems are ready. The user receives an acknowledgment, while the workflow continues behind the scenes.
Event-driven orchestration architecture bias
Event-driven orchestration architecture separates the sender from the receiver. Instead of System A calling System B and waiting for a response, System A sends a message or event. A broker, event layer, or orchestration platform receives it, routes it, and allows the next system or workflow step to process it when ready.
Recognizable patterns:
- Publish-subscribe: One event can notify multiple subscribers.
- Work queues: Tasks can be distributed across workers or consumers.
- Asynchronous request-reply: The requester receives a response at a later time via a callback, event, or status update.
- Event-triggered workflows: A message starts or advances a governed workflow.
Practical advantages:
- Systems are less tightly coupled.
- Spikes can be absorbed by queues or controlled routing.
- Retries can be handled without forcing users to resubmit work.
- Long-running workflows can continue without keeping an HTTP request open.
- Failures can be tracked at the workflow level instead of disappearing into scattered scripts.
Event-driven orchestration doesn't automatically guarantee reliability. Teams still need to define how messages are delivered, how many times failed actions should be retried, where failed messages should go, how duplicate messages are handled, how schemas are validated, how large payloads can be, whether message order matters, and how each message is correlated to the right workflow.
Where message-driven orchestration adds value
On its own, messaging moves events. Orchestration manages the flow. The broker can store and deliver messages, but it doesn't always know the complete business process. Down this pipeline, it struggles to determine whether payment must occur before fulfillment, whether an approval is required, whether a private network task has been completed, and whether an SLA was breached.
Event-driven orchestration adds a fully-realized control layer around the message flow.
Workflow orchestration platforms can:
- Receive events from APIs, webhooks, WebSocket routes, schedules, or system triggers.
- Route work using conditions, branches, and state transitions.
- Call REST or SOAP services where synchronous execution is required.
- Trigger custom functions or reusable automation logic.
- Execute private network tasks through a secure bridge agent where needed.
- Track execution status, input, output, response, exception, and duration.
- Apply retry, fallback, and timeout behavior to technical failures.
- Maintain audit history, SLA visibility, and process-level traceability.
For example, an order workflow may begin when an order event arrives. The orchestration layer validates the payload, checks inventory, routes payment, waits for confirmation, triggers fulfillment, sends notification, and records the final state. Each step can be visible within a single workflow instance, not as disconnected API calls.
This is useful for:
- Order processing
- Incident response
- Identity and access provisioning
- Finance approvals and invoice processing
- Hybrid ERP workflows
- Ticket synchronization across IT systems
- Secure server or application automation
Message-driven orchestration is especially valuable when the workflow is long-running, failure-prone, approval-heavy, or spread across cloud and on-premise systems.
Comparison between message-driven vs. API-first
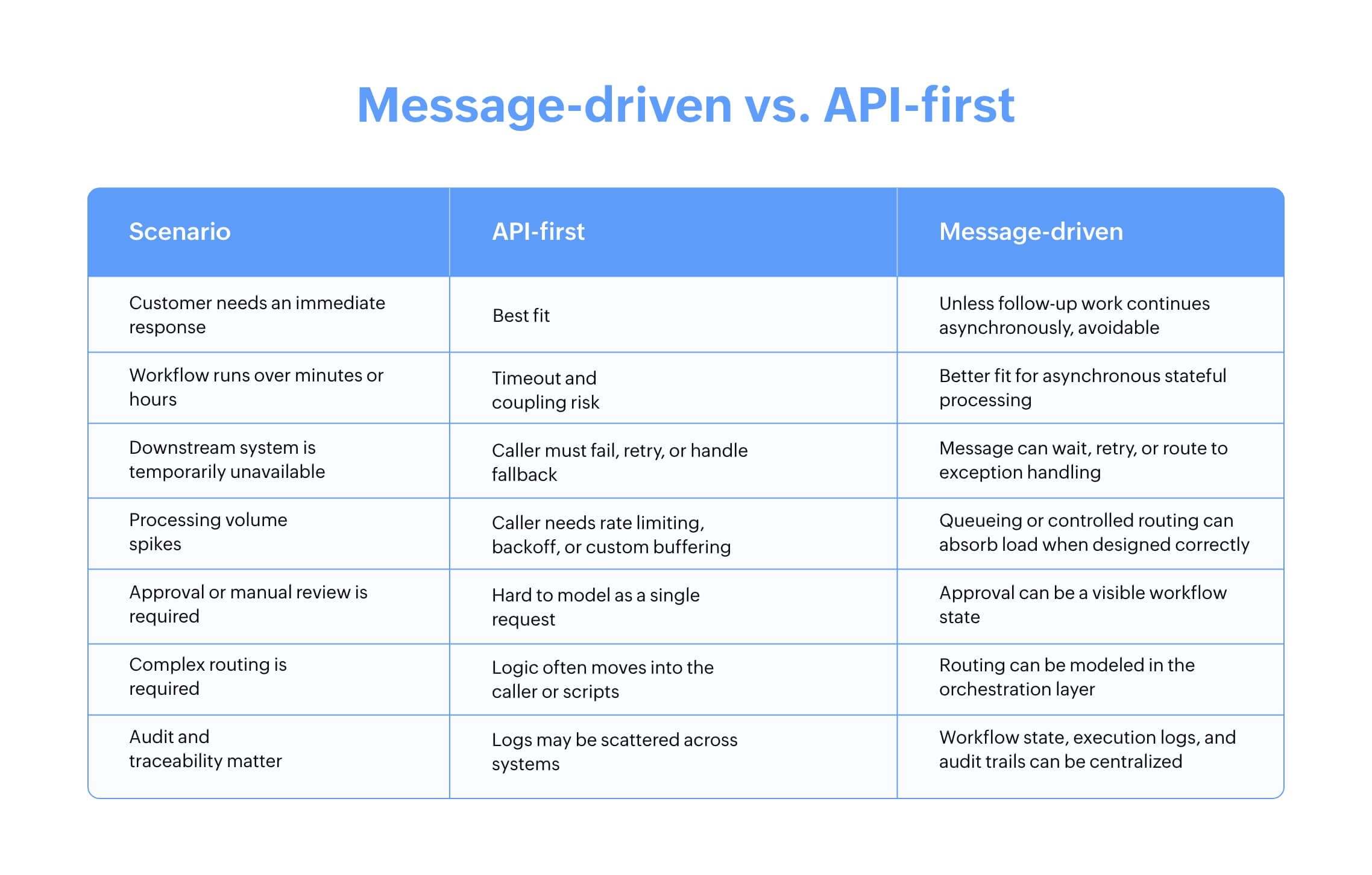
The key insight is that this isn't an either-or decision. APIs are still the right pattern for immediate requests, service exposure, and synchronous validation. Messages are better for workflow movement, resilience, fan-out, retries, and long-running coordination.
The strongest enterprise architecture uses both. APIs handle immediate interactions, messages and events trigger or advance workflows, and the orchestration layer coordinates the process and keeps state visible.
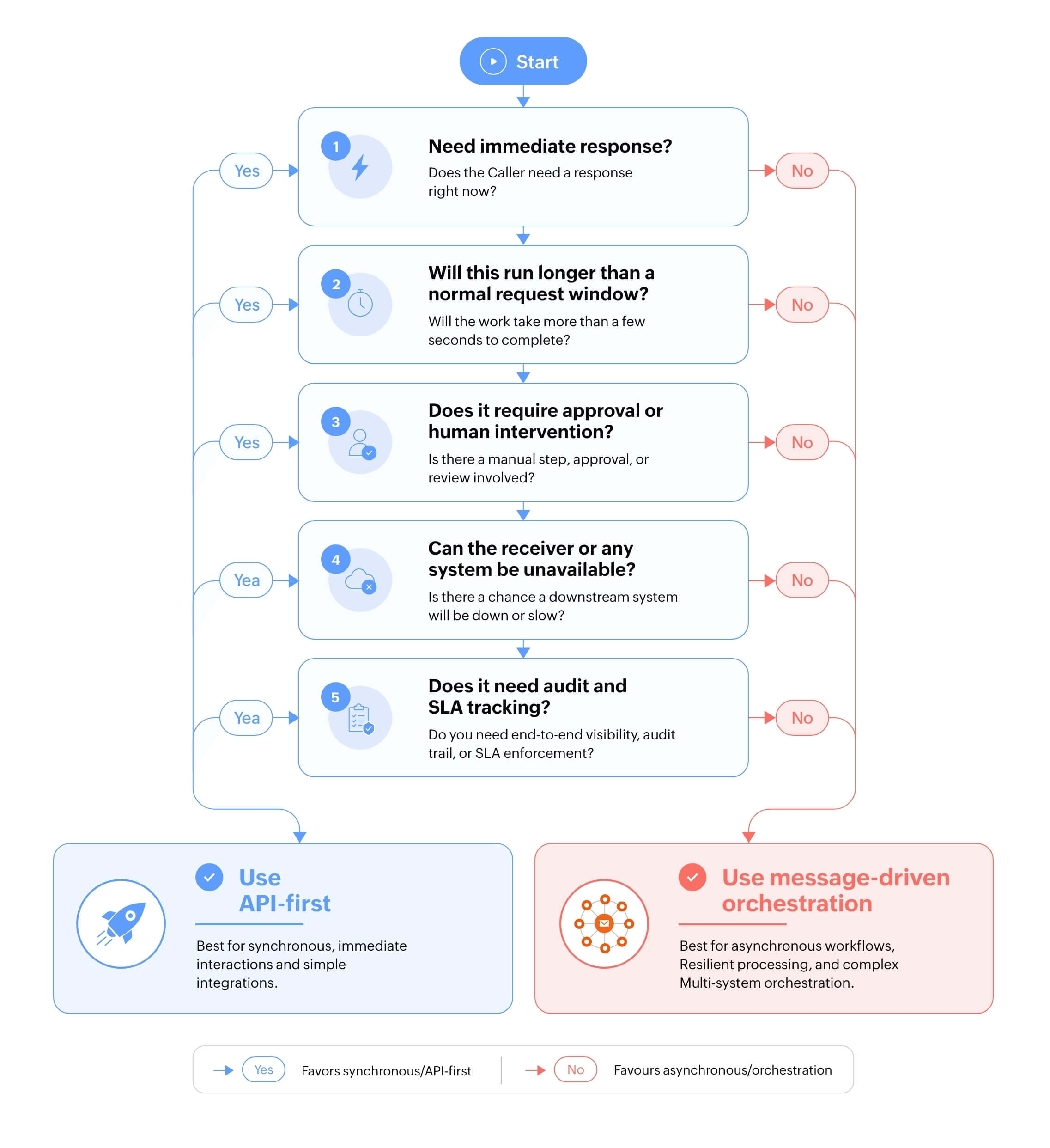
Implementing message-driven orchestration
Implementing message-driven orchestration starts with separating communication patterns from workflow responsibilities. APIs work best when the caller needs an immediate response, and the interaction is short-lived, deterministic, and expected to complete in real time. Operations such as authentication, validation, status checks, and direct data retrieval are well-suited for synchronous request-response communication because the caller depends on an immediate outcome.
The limitation appears when APIs are used to coordinate long-running workflows. Processes involving multiple systems, approvals, retries, private network execution, or conditional routing become tightly coupled when every step depends on a live synchronous response. If a downstream system slows down or becomes unavailable, the entire workflow can stall, time out, or fail.
Instead of pushing systems to respond in a rush, events trigger workflows that continue asynchronously while the orchestration layer maintains workflow state, routing logic, retries, SLA tracking, and audit history. This is possible because acceptance of work is separated from its completion, which is achieved through message-driven orchestration. These scenarios target high-value workflows like user onboarding, order processing, incident response, and internal provisioning, where execution could span minutes, hours, or days.
This model also improves resilience. If a downstream service is unavailable, the workflow can retry, queue the task, escalate, or move into exception handling without failing the entire process. The orchestration layer coordinates execution across APIs, approvals, internal systems, and private network resources while preserving visibility into every stage of the workflow.
An architecture that skews toward the most practical route here is the hybrid approach that best leverages the strengths of both orchestration styles. APIs handle immediate interactions and synchronous validation, message-driven orchestration handles asynchronous workflows, retries, approvals, and long-running coordination, and the orchestration layer becomes the control plane that keeps the workflow visible, auditable, and manageable across systems.
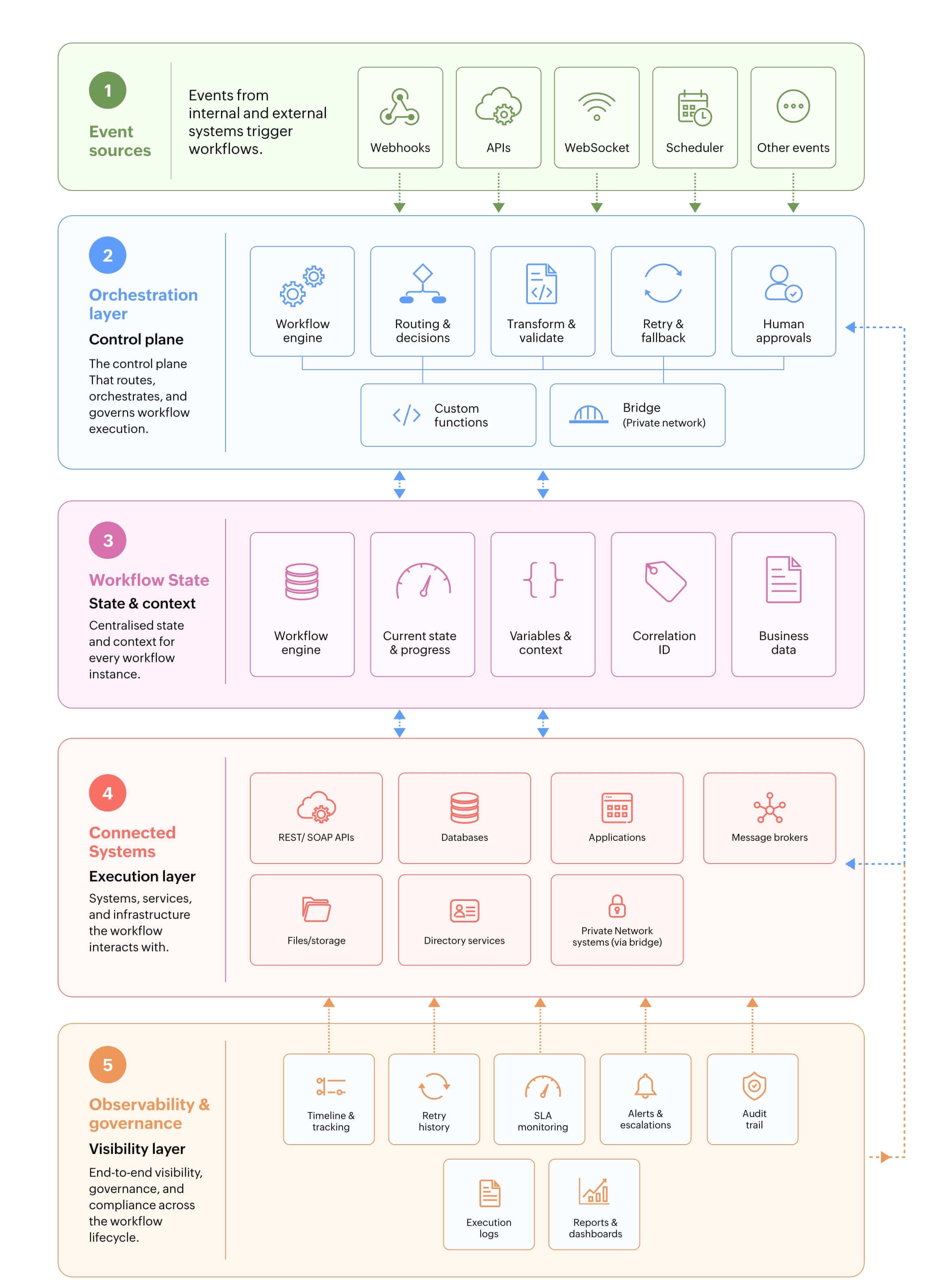
Architecture choices to evaluate
- External message broker or event layer: Useful for durable queues, high-throughput event streams, and subscriber-based distribution
- Workflow orchestration platform: Useful for state, routing, conditions, approvals, retries, execution logs, and governance
- Webhooks and web services: Useful for triggering workflows or calling external systems
- WebSocket endpoints: Useful for real-time, persistent message exchange and routed updates, but not a replacement for a durable queue unless the platform explicitly supports durable message guarantees
- Bridge-based execution: Useful when workflows must securely reach databases, applications, servers, directories, or file systems in a private network
Common implementation drawbacks
- Using messages for every integration, even simple request-response calls
- Treating a broker as a workflow engine
- Designing retries without idempotency
- Ignoring duplicate messages
- Losing correlation IDs across systems
- Logging events without preserving workflow state
- Sending sensitive payloads without masking, encryption, or access control
- Assuming message order when the architecture does not guarantee it
A practical design should define
- Message schema and versioning
- Correlation ID strategy
- Retry and fallback rules
- Dead-letter or exception handling
- Payload masking and retention
- SLA rules and escalation actions
- Access control for logs and execution data
- Testing strategy before publishing workflows
Why a hybrid approach is the best
API-first architecture is still foundational—it's not going away.
But enterprises are learning that request-response integration isn't enough for resilient, stateful, long-running workflows. When systems need to coordinate across approvals, internal applications, cloud services, private network resources, and audit requirements, message-driven orchestration provides a better operating model.
The future is hybrid. APIs will handle immediate interactions. Messages and events will drive asynchronous work. Orchestration platforms will provide the control layer that routes, tracks, retries, audits, and governs the entire flow.
Enjoying your reading?
Enjoy organization and visibility too!
Qntrl can help you organise, control and improve production and projects in your team.







